yum install libevent2-devel ncurses-devel git clone https://github.com/tmux/tmux.git cd tmux ./configure make
他のサイトだとlibeventのインストールにソースから持ってきているケースが多いが、yumでちゃんと入る
Just another WordPress site
yum install libevent2-devel ncurses-devel git clone https://github.com/tmux/tmux.git cd tmux ./configure make
他のサイトだとlibeventのインストールにソースから持ってきているケースが多いが、yumでちゃんと入る
このページを見ているということは故障して困ってこのページに来ているのだと思います。具体的にはキーボードとトラックパッドが効かず、ログイン画面から前に進めずに困って居ました。
念のためですが、ここに書いてあることを実行するのは自己責任でお願いします。
まず確認すべき点はここでしょう、幾つかのサイトを回った結果
という点が全て当てはまればIPDケーブルの故障を疑ったほうがよさそうです。
大体1万円くらいで修理が出来るようです。Macbookの修理にしてはお安いほうですね。大抵の人は出すのではないでしょうか。しかし自分でやってみたいという好奇心が止められなかったというのと、安く済むなら自分でやれば良いじゃないかという思いから自分でやることにしました。
ドライバーは星型のものとT5と呼ばれる型のものが必要になります。IPDフレックスケーブルはAmazon経由で中国から取り寄せました。




Macの裏蓋を外します。下側の中央にあるバッテリーの上を走るケーブルがIPD Flexケーブルです。これを交換するのが最終目標です。

はじめに電池のケーブルを基盤から外します。

次にIPD Flexケーブルの上側の留め具のネジを外し留め具を外します。

上側から外し粘着部分をペリペリ剥がして最後に下側の部分をコネクタから引っこ抜きます。

新品のケーブル(下)と古いケーブル(上)の比較画像です。

新品のケーブルを下のコネクタに差し込み、貼り付け、上のコネクタを差し込みます。おそらくこの時にあまり上の方にケーブルが余らないようにするのが良さそうです。
あとは分解したのと逆順で組み立てれば修理完了。
キャッシュはメインメモリの内容をその名の通りキャッシュしておくわけだが、メリットとしては主記憶からわざわざ近くに持って来なくてもアクセス先の周辺やそれ自身がアクセスされたことがあるといつのまにか近くにデータが持って来られているという算段だ。同じ変数を頻繁にアクセスする時間的局所性と近くのデータにアクセスしやすい空間的局所性を利用することで効率的に動作する。
スクラッチパッドメモリのことを知らない人は多いかもしれないが、先ほど説明した通り、スクラッチパッドメモリは小さなキャッシュではない普通のメモリに見える。これを普通のメモリとして変数を割り当てたりするのはナンセンスな使い方だ。せっかくの高速なメモリなのでキャッシュと同じように頻繁にアクセスされるような使い方が望ましい。
今年はもうネットワークスペシャリストの申し込みが終わったようだ。
ブログのネタが無くなって来たので昨年のネスペの合格について書いてみようと思う。
まずネスペを受けるに当たって一番大事にして欲しいのは過去問だ。
教科書を完璧にするという考え方はネットワークスペシャリストには通用しないように思える。なぜなら完璧にしようとすると暗記量が爆発してしまうからだ。一方で過去問を見ていると出題される分野がある程度偏っていることが見て取れると思う。特にセキュリティとシステムの冗長化に関しては毎年必ず出ると考えて良いだろう。
とは言いつつ、最初から過去問を解くことが出来るわけではない。従って、最初は教科書的なものを利用することになると思う。
最初に利用して欲しいテキストは”応用情報技術者”のネットワークに関する項だ。
この部分は丸暗記で良い。応用情報で出るようなネットワークの話はネスペを取るためには必要最低限暗記しなくてはならない骨格となるからだ。
おそらく応用情報のネットワークが出来るようになるとネスペの午前問題の4割程度は出来るようになるのではないか(当然応用情報のテキストは沢山あるのでどれを使うかによって大きく変わるだろうが)。
次はいわゆる道場で午前問題を完璧にするべきだ。問題を解くのは楽しい故、モチベーション維持に大変有効となる。
解くときは解説付きに限定すると良いだろう。
自分は通学中(片道一時間以上)に計算問題抜きで、自宅では計算問題ありで行なっていた。
大体合格点くらいの割合(6割)正解できるようになって来たら午後問題も並行して勉強し始めると良いと思う。
午後対策は初めに教科書について来た過去問の演習を行なった。さすがにお金を払っているだけの価値はある(Bookoffで200円だったがw)。数年分みっちりやるとなんとなくの感覚は掴めるようになるのではないだろうか。
しかしながらこれだけだと当然演習量が不足する。そこでIPAから過去問をダウンロードして何年分も演習することで補う。IPAは解説がそこまで十分でないのでわからないままになってしまう時がいくつかあった。そんなときは教科書を眺めたりネットで検索するなどして適宜解消していくことになるだろう。
試験前は道場で90%、午後で得意分野は80%、そうでない分野は60%くらい取れるように仕上げると…
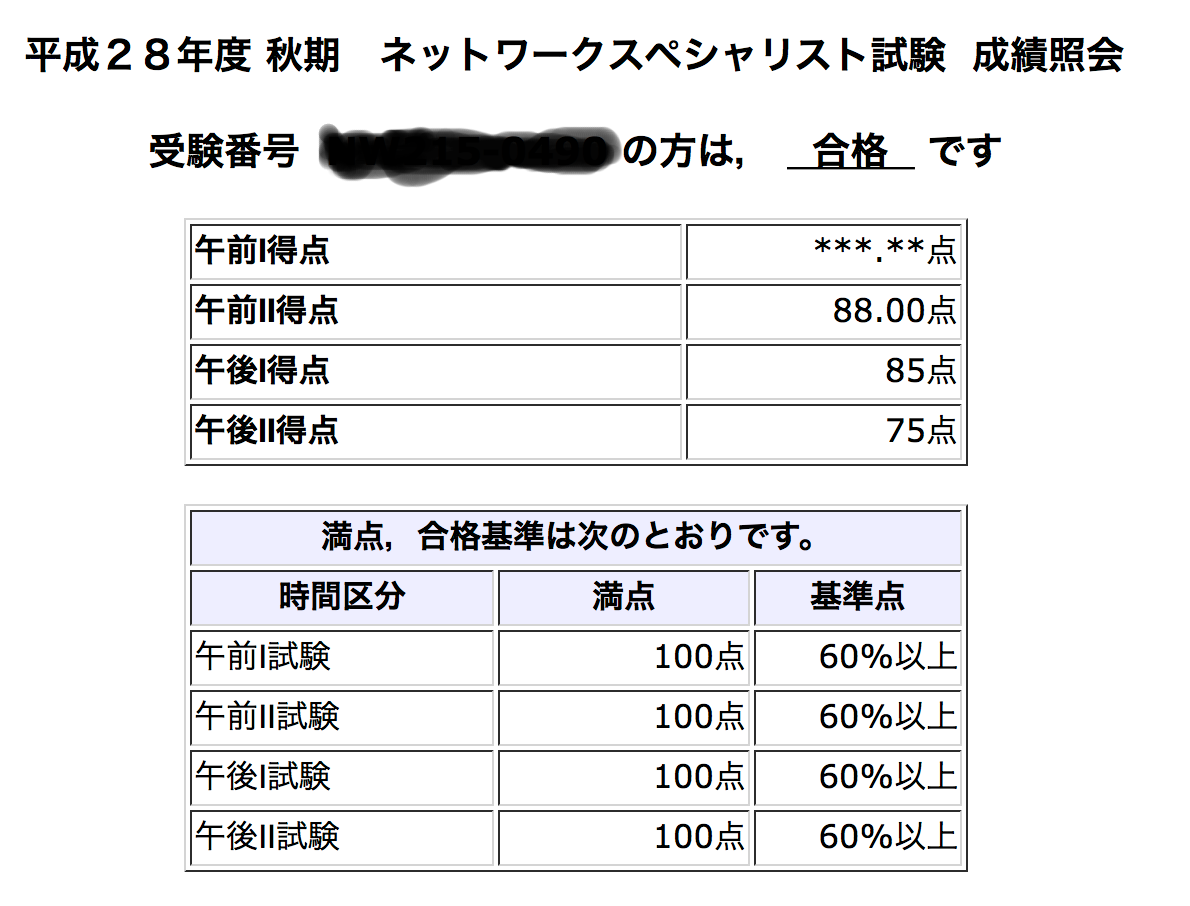
合格できる。
なんだかんだある程度余裕を持った合格でした。
それでも最短の努力で済んだかなという印象です。
イキリたかっただけです。ごめんなさい。
これから受験する方、頑張ってください。
DE0-nano-SoCはFPGAとARMの組み合わせのチップが載っているSoC FPGAの評価ボードであり、現在研究でこれを使っている。
その中でPython中でmmapを使いたいことがあり、嵌ったのでメモ
普通のPythonではmmapは普通に出来るらしい。
しかしながらDE0-nano-SoC上のPythonで走らせたところimport mmapの時点でNo such moduleと言われてしまった。
調べるのに時間がかかったが、どうやらライブラリが足らないんじゃないかということに落ち着き、aptで入れようとしたがyoctoだったので代わりにopkgで試した。が、しかし、ライブラリが無く、焦った。
パッケージ一覧を眺めたところpython-mmapというパッケージを発見、
無事インストールし、解決した。
opkg install python-mmap
おかしいなと思っていたんだ。gccのコンパイル中にCPUファンがずっと静かなんて。
以下の内容は簡単に言えばカスペルスキーのアンチウイルスソフトが原因かもしれないという話です。
題にあるようにbrew upgradeでgccがアップデートされるときに暫く待っても全く終わる気配がなく、悩んでいました。Ctrl-Cしてまた後日やるということを何回か繰り返した今日、どの処理が重いのだろうと思ってアクティビティモニタを見てみました。そしたらCPU使用率100%を占めていたのは”kav”じゃないですか!!”kav”はカスペルスキーのアンチウイルスソフトのプロセスです。そこでカスペルスキーの保護を一時的にやめてみたら上手く動くようになりました。
もしかしたら最近Sierraにしたのが原因なのかもしれないと思っていたのですが、そうでなくてよかったです。(良くはないが)
僕は大学でHPCやコンピュータアーキテクチャを専攻する身であり、そのような分野では基本的にはISAを直に考え、HW Specificなネイティブコードについて考えたり扱うことが多い。
当然ネイティブコードの方が早いように思われるのかもしれないが、インターネットを介して多くのアプリケーションがやり取りされる今日、一つのアプリケーションでも複数のアーキテクチャに対してサポートしなければならないようになってきた。
今までのPCアプリケーション開発ではi386をターゲットにしてコンパイルしていたかもしれないが、これからはARMノートPCが来る。そして当然ARMノートPCの上でも性能は要求される。常にi386コードをエミュレーションして動作させるのはおそらくユーザーが納得しないだろう。
そこで重宝されるのがインターネット上での頒布はバイトコードで行う手法だと考えている。バイトコードをアーキテクチャから独立した形式で設計し、IA-64でもARMでもMIPSでももしかしたらこれから登場するかもしれないアーキテクチャにも対応させるのだ。
元々このアイディアはAndroidが実装していた。Android開発ではDalvikアーキテクチャという仮想的なアーキテクチャの上でのバイトコードを出力し、それをAndroid上でJITコンパイルで実行していた。これをLolipopになってからはARTという技術が導入されAOTコンパイルを可能にし、実行速度を改善した。しかしインストール時やアップデート時のコンパイルが必要となるため、この部分に時間がかかり、結局JIT形式に落ち着いたようだ。
バイトコードを利用するのはただ単に異なるアーキテクチャに対応させるためだけが目的ではない。たとえばARMで言えばNEON、Intelで言えばAVX/SSEのベクトル命令は性能を上げる上で利用したいものだ。しかし、これらは同じARMやx86_64でもプロセッサのグレードや想定使途などで細かく仕様が異なる。これを吸収することが出来るのがバイトコードなのではないかと考えているのだ。
SIMDを使う以外にもこれからのプロセッサはキャッシュよりもローカルメモリを使うようになるのではないかと思っているので、このローカルメモリのサイズの違いに合わせたネイティブコードを出力できるという点でもJIT/AOTは優れていると感じる。
(さらに抽象度を上げて言えば、ハードウェアスペシフィックな最適化を行うことが可能ということがとても良いのだ)
さっきからバイトコードと言っているものの、単に機械語よりは抽象度が高いが、高機能ではない中間表現として扱っているだけで、JavaバイトコードとかDalvikバイトコードが良いとか言っているわけではない。個人的にはLLVMのbcファイルの”LLVMビットコード”を推している。
Top500は世界で最も計算能力がある500台がリストになって掲載されている。
実際にはリストに載っていないスパコンはいっぱいあるのではないかという話を聞くが、そういうのは大体が軍事目的なのだろう。
さて、今の1位はSunway TaihuLightだ。
神威・太湖之光と書くらしい。
CPUはSW26010という中国独自開発のCPUだ。
これはアメリカの輸出制限の影響だと聞いたことがある。
動作周波数は1.45GHzと低い。これのおかげか、全体の消費電力は15.3MWで電力効率に優れる。
メモリバンドはそこまで大きくないようだ。
2位と比べると3倍程度性能が高く驚くばかりだ。
トップ勢のプロセッサを見ていくと2位、5位、6位とXeonPhiが目立つ。
一方、GPUが優位なはずなのに3位の次は8位だ。
会社で見ていくと3位、5位、8位、それ以降もCray社がとても多い。
Cray社のチップを使っているかどうかは分からないが、やはりそれだけのノウハウを持っていて、スパコンの販売実績も十分だからだろう。
今までssh越しにXを使いたいときはオプションに-Xを指定してXfowardingを使っていた。
が、しかし、最近になってこれが失敗するようになってしまって困っていたのでメモ。
よく見ると
“Warning: untrusted X11 forwarding setup failed: xauth key data not generated”
というエラーが表示されていた。
どうやらセキュリティの問題らしい。
ここでオプション-Xの代わりに-Yを使うことで、相手を強制的に信頼させXfowardingを使うことが出来る。
これでも
“Warning: No xauth data; using fake authentication data for X11 forwarding.”
というエラーは出るが、GUIアプリケーションを起動させてみると成功する。
時間があったらもっと調べていきたい。
FPGAは、普通のハードロジックと比べて10~100倍程度遅いとされているが、最近どんどん速くなってきているようだ。
自分はまだこの業界に片足を突っ込んで日は浅いが、alteraがintelに買収された真っ只中を見ている。
intelに買収されたことによる一番のメリットはおそらくFPGAのプロセスルールが急激に進歩すると考えられることだ。
プロセスルールの微細化といえばintelが主導してやってきていて7nmなどが出ると言われているが、FPGAのプロセスルールは何十というオーダーだったのが一気に十何nmというオーダーになるのだ。
Altera側もXilinxに大きな差をつけられるので経営的に良かったのだろうし、intelもアクセラレータ候補を手に入れたことになる。
もしかしたらFPGAがコンシューマPCの中で計算に使われる時代が近いのかもしれない。